近期,Hugging Face携手英伟达及约翰霍普金斯大学的研究人员,共同推出了BERT模型的全新升级版本——ModernBERT。这一新版本不仅在效率上有所提升,更突破了原有模型在处理长文本上的限制,能够支持高达8192个Token的上下文处理。
自2018年问世以来,BERT模型一直是自然语言处理领域的热门之选,其在Hugging Face平台上的下载量仅次于RoBERTa,每月下载量超过6800万次。然而,随着技术的不断进步,原版BERT模型在某些方面已略显陈旧。
面对这一挑战,Hugging Face及其合作伙伴借鉴了近年来LLM领域的最新进展,对BERT的模型架构和训练过程进行了全面优化,最终推出了ModernBERT。这一新版本旨在接替原版BERT,成为自然语言处理领域的新标杆。
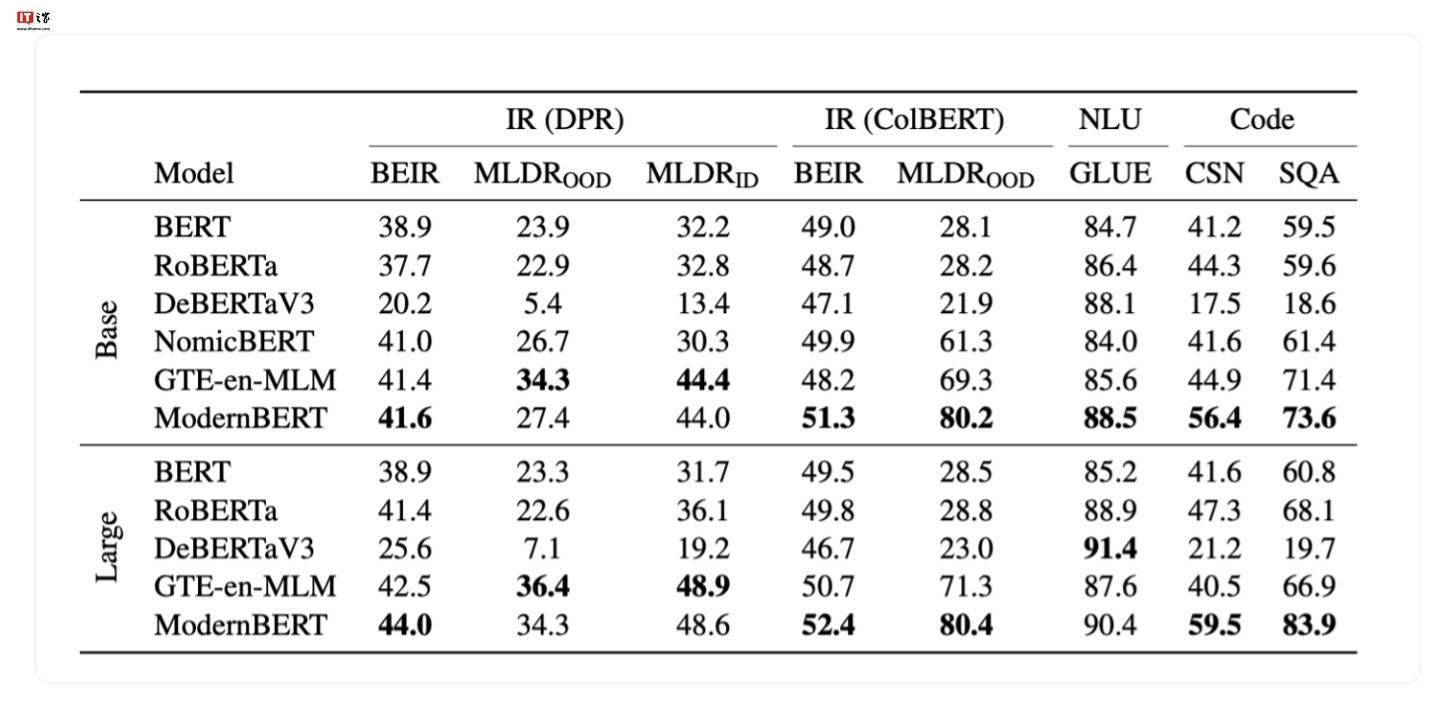
ModernBERT在基准测试中的表现令人瞩目。开发团队使用了多达2万亿个Token的数据进行训练,使得该模型在多种分类测试和向量检索测试中均取得了业界领先的成绩。这一成果不仅验证了ModernBERT的先进性,也展示了开发团队在模型优化方面的深厚实力。
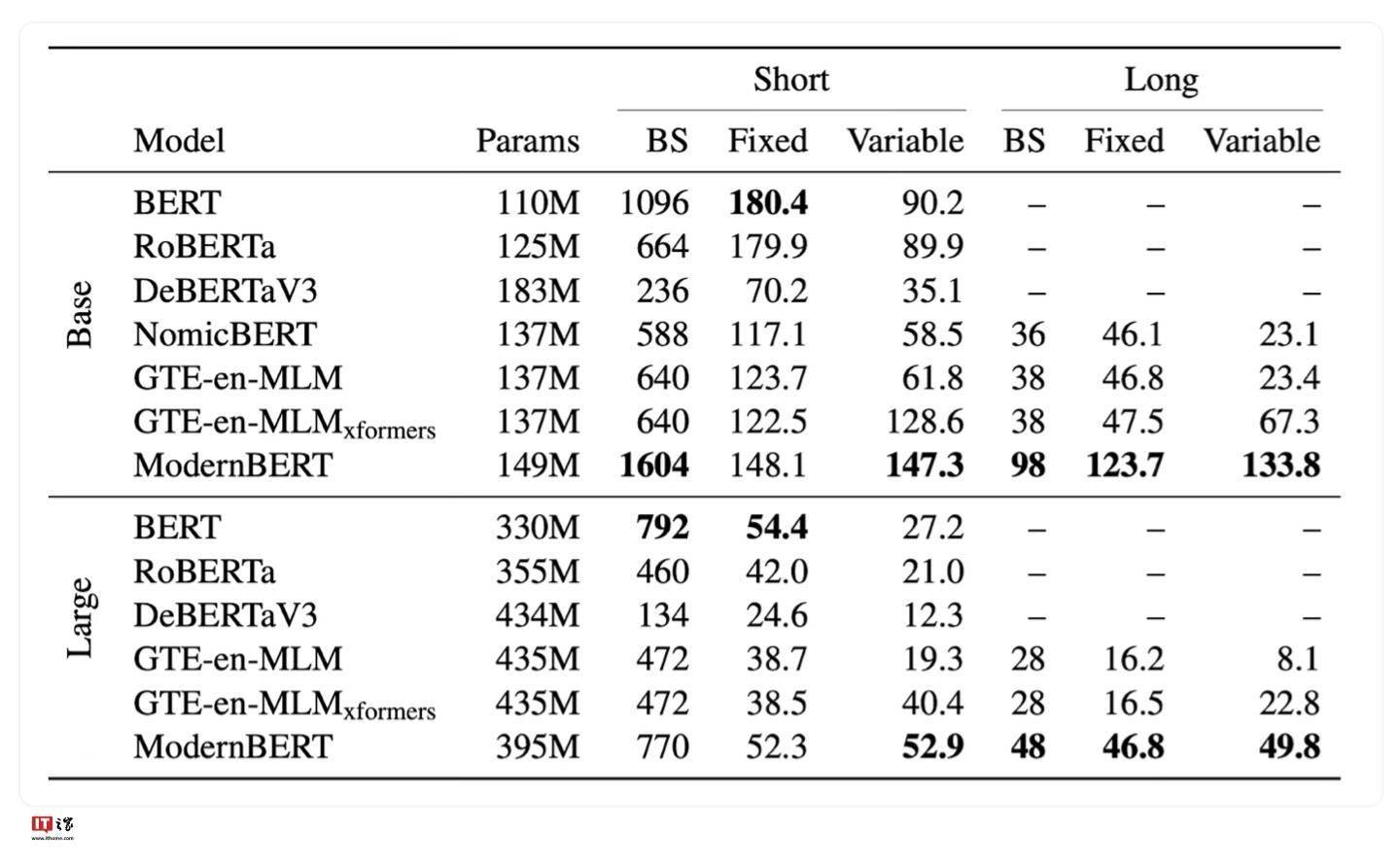
为了满足不同用户的需求,开发团队还推出了两个版本的ModernBERT模型,分别是拥有1.39亿参数的精简版和拥有3.95亿参数的完整版。这两个版本均提供了强大的自然语言处理能力,用户可以根据自己的实际需求进行选择。
目前,ModernBERT的模型文件已经公开发布,用户可以通过指定的项目地址进行下载和使用。这一新版本的推出,无疑将为自然语言处理领域的发展注入新的活力。